扫二维码与项目经理沟通
我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流
本章介绍分布式架构的底层技术。主要说明面试过程中可能被问到的技术点。

Zookeeper 分布式
Zookeeper是一个分布式的、开源的分布式应用程序协调服务。它是集群的管理者,监视着集群中各个节点的状态,并根据节点提交的反馈进行下一步合理的操作。
对于客户端的读操作,可以被集群中任意一台机器处理。如果读请求在节点上注册了监听器,这个监听器也是由所连接的机器来执行
对于客户端的写操作,这些请求会同时发给其他的zookeeper机器并达成一致后,请求才会返回成功
因此,随着集群机器的增多,读请求的吞吐会提高,而写请求的吞吐会下降
有序性是Zookeeper的另一个特点,所有的更新操作都是全局有序的;每个更新都有唯一的时间戳,称为zxid(Zookeeper Transaction Id);而读请求只会相对于更新有序,也就是读请求的返回结果中会带有这个zookeeper的最新zxid
文件系统 和 通知机制
Zookeeper提供了一个多层级的节点命名空间(节点称为znode)
与文件系统不同的是,它的每个节点都可以设置关联数据,而文件系统只有文件节点可以存放数据而目录节点不行
Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,所以它不能存放大量的数据,每个节点的存放数据上限是1M
PERSISTENT,持久化目录节点:客户端与Zookeeper断开连接后,该节点依旧存在PERSISTENT_SEQUENTIAL,持久化顺序编号目录节点:客户端与Zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号EPHEMERAL,临时目录节点:客户端与Zookeeper断开连接后,该节点被删除EPHEMERAL_SEQUENTIAL,临时顺序编号目录节点:客户端与Zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号客户端注册监听它关心的目录节点,会对该znode建立一个watcher事件,当该znode发生变化(数据删除、被删除、子目录节点增加删除等)时,Zookeeper会通知客户端
命名服务是指通过指定的名字来获取资源或服务的地址,即利用Zookeeper创建一个全局的路径,也就是唯一的路径,这个路径可以作为一个名字,指向集群中的机器、提供服务的地址、一个远程对象等
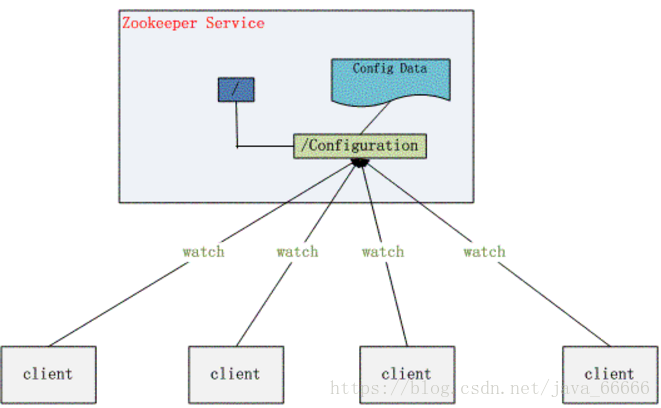
程序分布式的部署在不同的机器上,将程序的配置信息放在zookeeper的znode下,当配置发生变化时,也就是znode发生变化时,利用watcher通知各个客户端,从而更改配置
所谓集群管理无非两点,是否有机器退出或加入、选举master
第一点,所有机器约定在父目录下创建临时目录节点,然后监听父目录节点的子节点变化信息;如果有机器挂了,该机器就会与Zookeeper断开连接,其创建的临时目录就会删除,此时就会通知所有机器,有个兄弟机器挂了;同理,机器加入也是一样
第二点,所有机器创建临时顺序编号目录节点,每次都选取编号最小的机器作为master
有了Zookeeper的一致性文件系统,锁变得简单。锁服务可以分为两类:保持独占,控制时序
对于保持独占,我们将znode看作一把锁,通过createznode的方式来实现;所有客户端都去创建/distribute_lock节点,最终成功创建的那个客户端也就获取了这把锁,用完删掉/distribute_lock节点,即可释放锁
对于控制时序,/distribute_lock已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选举master一样,编号最小的获得锁,用完删除自己的临时顺序编号目录节点
在分布式锁的场景下,会提前在Zookeeper中创建一个持久节点ParentLocker(名字叫什么都可以)
当客户端要获取锁时,需要在ParentLocker下创建一个临时顺序编号节点Locker-n,首先,查找ParentLocker下的所有临时子节点并排序,并且判断自己创建的Locker-n是不是顺序编号最小的,如果是,则临时节点Locker-n创建成功,也就是获取锁成功;如果不是最小的,此时找到排序仅比自己靠前的节点,向其注册监听Watcher,监听其是否存在(exist),也就是该客户端获取锁失败,进入等待;当前一个节点被删除时,客户端会收到通知,然后再次判断自己是不是最小的,如果是则获取锁成功,如果不是,则再重复以上步骤

Zookeeper的核心是原子广播,保证了各个Server之间的同步;实现这个机制的协议叫做Zab协议。Zab协议有两种模式,恢复模式(选主)和广播模式(同步)。当服务启动或者领导者崩溃后,Zab进入恢复模式;当选举了新的领导者,并且大多数Server和leader的状态同步完成之后,恢复模式就结束了。状态同步保证了leader和server之间有相同的系统状态
采用递增的事务ID:zxid来标识,所有的proposal(提议)都会加上zxid。zxid是64位的数字,高32位是epoch,用来标识leader是否发生变化,如果是新选举的leader,则epoch会递增;低32位是递增计数的。当有新的proposal提出时,首先向其他server发出事务执行请求,如果有超过半数的机器都能执行且能够执行成功,然后才会开始执行
当leader崩溃或失去大多数follower,这时会进入恢复模式。选举算法有两种:一种是基于basic paxos实现的,一种是基于fast paxos实现的,默认是fast paxos。
basic paxos算法
a) 每个Server上的选举线程由当前Server发起选举的线程担任,主要职责是对各个投票结果进行统计,选举 出新的leader
b) 选举线程向所有Server发起一次询问(包括自己)
c) 选举线程收到回复后,验证是否是自己发出的询问(验证zxid是否一致),然后获取对方的myid,将之存储到当前询问的对象列表中,最后获取对方提议的leader相关信息(myid,zxid),存储到当次选举的投票记录中
d) 收到所有的Server回复后,计算出zxid大的Server,然后统计它的票数,如果它获得了n/2+1的Server票数,则设置为新的leader。否则,重新再次选举
通过该选举流程可以得出,要使leader获得多数Server的支持,Server的总数必须是奇数2n+1,且存活的Server数目不得少于n+1
fast paxos算法
在选举时,首先向所有Server提议自己要成为leader,当其他Server收到提议后,会进行PK(zxid大myid大的获胜),并回复同意还是拒绝,重复这个流程,就会选择出一个新的leader
选完leader后,进入同步流程
zk的负载均衡可以调控,nginx只能调权重,其他的都要自己写插件,但是nginx的吞吐量比zk大得多
一个watch事件是一个一次性的触发器,当被设置了watch的数据发生了变化时,服务器会将这个变化发送给设置了watch的客户端
public Zookeeper(String connStr, int sessionTimeout, Watcher watcher)),服务器端只是存储了是否设置了watch的布尔变量另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。

我们在微信上24小时期待你的声音
解答本文疑问/技术咨询/运营咨询/技术建议/互联网交流
微信二维码
移动版官网